 |

"The Tower of Babel"
by Pieter Bruegel the Elder
|
To begin with, KMS is a term that does not have a consensus definition. Yes, we know what the initials KMS stand for and we have an understanding of what a system is. The IPO model: Inputs, Processes, Outputs, defines a basic system that when we add feedback, is a fair description of a KMS in a learning organization. We get further insight into what an information system is from Alter (1999) who defines an information system as humans or machines limited to processing information by performing six types of operations: capturing, transmitting, storing, retrieving, manipulating, and displaying. This is further refined by Churchman (1979, p. 29) who defines a system as "a set of parts coordinated to accomplish a set of goals;" and that there are five basic considerations for determining the meaning of a system:
- System objectives, including performance measures
- System environment
- System resources
- System components, their activities, goals and measures of performance
- System management.
Churchman (1979) also noted that systems are always part of a larger system and that the environment surrounding the system is outside the system's control, but influences how the system performs. These definitions are useful but don't fully describe a KMS. Reviewing the literature provides definitions that range from purely technical to something that includes organizational issues. These definitions are summarized below.
KMS Definitions
Alavi and Leidner (2001, p. 114) defined a KMS as “IT (Information Technology)-based systems developed to support and enhance the organizational processes of knowledge creation, storage/retrieval, transfer, and application.” They observed that not all KM initiatives will implement an IT solution, but they support IT as an enabler of KM. Maier (2002) expanded on the IT concept for the KMS by calling it an ICT (Information and Communication Technology) system that supported the functions of knowledge creation, construction, identification, capturing, acquisition, selection, valuation, organization, linking, structuring, formalization, visualization, distribution, retention, maintenance, refinement, evolution, accessing, search, and application. Stein and Zwass (1995) define an Organizational Memory Information System (OMS) as the processes and IT components necessary to capture, store, and apply knowledge created in the past on decisions currently being made. Jennex and Olfman (2004) expanded this definition by incorporating the OMS into the KMS and adding strategy and service components to the KMS.
KMS Classifications
Additionally, we have different ways of classifying the KMS and/or KMS technologies where KMS technologies are the specific IT/ICT tools being implemented in the KMS. Alavi and Leidner (2001) classify the KMS based on the Knowledge Life Cycle stage being predominantly supported. This model has four stages, knowledge creation, knowledge storage/retrieval, knowledge transfer, and knowledge application and it is expected that the KMS will use technologies specific to supporting the stage for which the KMS was created to support. Marwick (2001) classifies the KMS by the mode of Nonaka's (1994) SECI model (Socialization, Externalization, Combination, and Internalization) being implemented. Borghoff and Pareschi (1998) classify the KMS using their Knowledge Management Architecture. This architecture has four classes of components: repositories and libraries, knowledge worker communities, knowledge cartography/mapping, and knowledge flows; with classification being based on the predominant architecture component being supported. Hahn and Subramani (2001) classify the KMS by the source of the knowledge being supported: structured artifact, structured individual, unstructured artifact, or unstructured individual. Binney (2001) classifies the KMS using the Knowledge Spectrum. The Knowledge Spectrum represents the ranges of purposes a KMS can have and include: transactional KM, analytical KM, asset management KM, process-based KM, developmental KM, and innovation and creation KM. Binney (2001) does not limit a KMS to a single portion of the Knowledge Spectrum and allows for multi-purpose KMS. Zack (1999) classifies KMS as either Integrative or Interactive. Integrative KMS support the transfer of explicit knowledge using some form of repository and support. Interactive KMS support the transfer of tacit knowledge by facilitating communication between the knowledge source and the knowledge user. Jennex and Olfman (2004) classify the KMS by the type of users being supported. Users are separated into two groups based on the amount of common context of understanding they have with each other resulting in classifications of: process/task based KMS or generic/infrastructure KMS. This leads to two approaches to building a KMS: the process/task based approach and the infrastructure/generic system based approach.
The process/task based approach focuses on the use of knowledge by participants in a process, task or project in order to improve the effectiveness of that process, task or project. This approach identifies the information and knowledge needs of the process, where they are located, and who needs them. The KMS is designed to capture knowledge unobtrusively and to make knowledge available when needed to whom needs it.
The infrastructure/generic system based approach focuses on building a base system to capture and distribute knowledge for use throughout the organization. Concern is with the technical details needed to provide good mnemonic functions associated with the identification, retrieval, and use of knowledge. The approach focuses on network capacity, database structure and organization, and knowledge/information classification.
The key difference between these two approaches is that the process/task approach has known users and knowledge requirements while the infrastructure/generic system approach does not. The process/task approach focuses on a group of known users with a common context of understanding, resulting in a KMS that does not need to capture context with the knowledge. The infrastructure/generic KMS must capture context with the knowledge to ensure that users use the knowledge correctly. Finally, the process/task approach tends to more immediate payoffs and visible success while the infrastructure/generic system approach tends to long-term payoff with little quick visible success.
Both approaches may be used to create a complete organization-wide KMS. The process/task based approach supports specific processes and projects, getting users involved and motivated quicker, while the infrastructure/generic system approach integrates all knowledge into a single system, leading to bigger dividends when successful because the knowledge can be leveraged over the total organization instead of just a process or project. The process/task approach is preferred for identifying localized knowledge needs and meeting them, and for smaller organizations with well-defined knowledge goals and strategy. The infrastructure/generic system approach is preferred when specific knowledge users and needs are not known, but the organization knows knowledge use is necessary. It gives the system developers time to determine needs while building the KMS infrastructure. Morrison and Weiser (1996) support the dual approach concept by suggesting that a KMS be designed to combine an organization's various task/process based KMSs into a single environment and integrated system.
So What Is A KMS?
I favor a holistic view of systems and the KMS and include the processes and users as part of the KMS, not just the IT components. I also agree that a KMS should address all aspects of the knowledge life cycle and includes components from the KM architecture. Figure 1 is a generic process chart of a typical KMS.
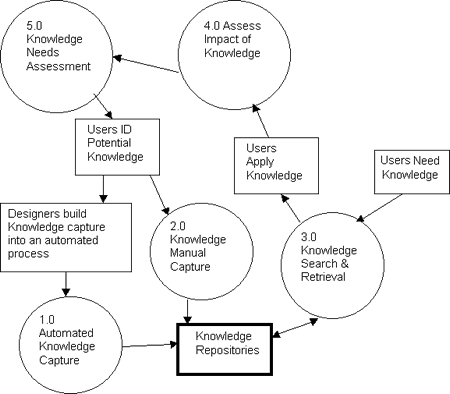
Figure 1: Process Chart for a Generic KMS
The KMS consists of processes and technologies for identifying and capturing knowledge, knowledge repositories, processes for storing, searching, retrieving, and displaying knowledge, and users. It is not required that the KMS be computer-based as two capture processes are shown. The first represents manual capture by individuals who identify knowledge to be retained and then take the necessary steps to place the knowledge in a repository. The second is a capture process integrated into automated processes. An automated capture process requires that someone identify knowledge products or artifacts of the process up front so that system designers can build databases and automated processes into the system to capture the knowledge. Figure 1 is a high-level process diagram for a KMS. The spheres or “bubbles” represent KMS processes. Regular squares represent actions or needs from the KMS users. The heavy lined square represents knowledge repositories. Figure 1 also indicates that a KMS includes a feedback loop. As knowledge is used its impact should be monitored and assessed. Knowledge found to improve organizational effectiveness should be retained and possibly expanded. Knowledge that is not improving effectiveness should be analyzed to determine what data, information, and/or knowledge is needed and the knowledge capture process modified to include the new data, information, and/or knowledge. Users are emphasized since they are the ones using knowledge. IS personnel may be users but in general they should not be the ones identifying knowledge needs.
Knowledge Repositories
Key to the KMS is knowledge repositories. Ultimately there are three types of knowledge repositories: paper documents, computer based documents/databases, and self memories:
- Paper documents incorporate all hard copy documents and are organization-wide and group-wide references that reside in central repositories such as a corporate library. Examples include reports, procedures, pictures, video tapes, audio cassettes, and technical standards. An important part of this knowledge is in the chronological histories of changes and revisions to these paper documents as they reflect the evolution of the organization's culture and decision-making processes. However, most organizations do not keep a separate history of changes, but do keep versions of these documents.
- Computer based documents/databases include all computer-based information that is maintained at the work group level or beyond. These may be made available through downloads to individual workstations, or may reside in central databases or file systems. Additionally, computer documents include the processes and protocols built into the information systems. These are reflected in the interface between the system and the user, by who has access to the data, and by the formats of structured system inputs and outputs. New aspects of this type of repository are digital images and audio recordings. These forms of knowledge provide rich detail but require expanded storage and transmission capacities.
- Self-memory includes all paper and computer documents that are maintained by an individual as well as the individual's memories and experiences. Typical artifacts include files, notebooks, written and un-written recollections, and other archives. These typically do not have an official basis or format. Self-memory is determined by what is important to each person and reflects his or her experience with the organization.
Repositories have overlapping information and knowledge as shown in Figure 2. Paper documents are indexed or copied into computer databases or files, self memory uses paper and computer based documents/databases, computer databases or files are printed and filed. Spheres for self-memory and others' memory reflect that organizations consist of many individuals, and that the knowledge base contains multiple self-memories. Finally, the relative size of each sphere depends on the nature of the organization. Organizations that are highly automated and/or computerized would be expected to have a greater dependence on computer-based repositories while other organizations may rely more on paper or self-memory based repositories.
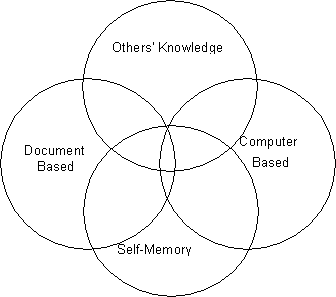
Figure 2: Knowledge Repositories
Use Of Knowledge Repositories
Should organizations focus more on computerized repositories or on self-memory repositories? I naturally encourage computerized repositories as I believe these repositories provide a measure of permanence coupled with better tools for searching and retrieving knowledge. However, organizations should consider the transience and experience level of their workers.
Sandoe and Olfman (1992) found that the increasing transience (or mobility) of organizational workers requires a shift in the location of knowledge. Organizations that have large numbers of transient workers are at risk of losing organizational knowledge if it is allowed to remain in self memories. These organizations need to capture and store knowledge in more concrete forms such as paper or computer-based repositories. They also suggest that stronger attempts should be made to capture the unstructured, abstract information and knowledge in concrete forms. Additionally, Jennex and Olfman (2002) found that new workers in an organization have trouble using the document and computer-based repositories and rely on the self-memories of longer-term members. This tendency continues until the new member gains sufficient context to understand and use the information and knowledge stored in the concrete paper and computer-based repositories. While these guidelines seem to be contradictory because transient organizations will tend to have more new members, the authors do emphasize that organizations should minimize reliance on self-memories for the retention of concrete, structured knowledge while using self-memories as the mechanism for teaching organizational culture and passing on unstructured, abstract knowledge.
This illustrates the role of organizational culture as a repository of knowledge. Organizational culture provides the context for using knowledge, and guides members in how to interpret and use it. Organizational culture uses the three types of repositories to reflect the culture as represented in procedures, guidelines, and work processes; the unstructured, abstract knowledge that includes reflexive (e.g., habits and norms) knowledge, anecdotes, stories, and histories that are passed on by organizational members, providing new members with the context for using the knowledge.
Designing a KMS
Figure 1 illustrates the basic process components of a KMS. These are capturing, storing, searching, retrieving, using, and assessing knowledge. A successful KMS should perform these functions well. However, other factors can influence KMS success. Mandviwalla, et al. (1998) describe several issues affecting the design of the KMS:
- Focus of the KMS: designers need to reconcile perspectives on knowledge from different organizational groups
- Quantity: designers need to decide how much knowledge should be captured and in what formats; decisions need to be made to ensure information overload does not occur and that storage repositories are not overloaded with video or other images or with documents
- Filters: who decides what knowledge is
- Role of self memory: what reliance and/or limitations are placed on the use of individual memories in the KMS
- Storage: what devices, locations, and capacities are needed and at what cost
- Retrieval: how is information and knowledge organized and stored so that it can be searched and linked to appropriate events and use
- Integration/Re-integration: since knowledge can be stored in various formats and repositories, designers must create processes for integrating the various repositories and for re-integrating information and knowledge extracted from specific events.
Mandviwalla, et. al. (1998) proposed some generic KMS design requirements to address these issues. These requirements are based on the key informational elements of work — data, time, space, and activities.
Data requirements include types of data, representation of information and knowledge, and capture of data, information and knowledge.
Knowledge repositories need to be designed to accommodate several different data types:
- Metadata defines associations between work activities, processes, and context. Metadata can include email, organizational charts, procedures, and guidelines.
- Structured data are formal records from activities and processes. Structured data can include completed forms, procedures, notifications, and listings.
- Semi-structured data are typically paper documents used in work, but they can also be digital documents.
- Unstructured knowledge include documents, video, audio, and images.
- Temporal data are for work over a period of time. Temporal data includes all the previous forms of data stored over the period of an activity or event.
Representation is the key to the use of knowledge. Two issues define it: how the previous forms of data are organized and stored, and how this data is represented in the user interface. The traditional database relational structure is sufficient for much of this data, but is difficult to use with digital documents, metadata, and unstructured data. Hobbs and Pigott (2001) provide a methodology for conceptually modeling and designing multimedia databases. Hyperlinks and other approaches can be used to link data within digital documents. Numbering systems and database reference links can be used to represent links between paper documents and activities. However, representation through the user interface is always difficult. Users need to be able to visualize data in a way that will enhance their cognitive processes. For example, Eppler (2001) provides various knowledge maps supporting different contextual uses of data, information and knowledge. Ultimately designers will need to analyze the needs of the KMS users to see what user interface representations work best.
Finally, capture refers to how the data, information and knowledge are placed into knowledge repositories. Methods vary from automatic capture to updating knowledge repositories by designated personnel. KMS designers need to select the methodology that fits the culture, politics and work processes of the organization.
Time and space requirements are related to where the knowledge is used and how long it is useful. All knowledge has a life cycle. As knowledge ages it needs to be purged once it is no longer useful. Designers need to consider retention times and methods for identifying outdated knowledge. Space depends on the architecture of the KMS. Users rarely access knowledge from a single location. Designers need to provide networks and methods for accessing knowledge remotely or from distributed work locations.
Activities indicate where knowledge is used. Designers need to be aware of the work activities and processes that utilize knowledge so that they can ensure it is available to support those activities. This requires designers to coordinate users, knowledge, and work activities and to establish boundaries on use. Boundaries are necessary to establish security and protect the knowledge.
Jennex and Olfman (2000) studied successful KMSs and proposed a set of design recommendations based on applying Delone and McLean's (1992 and 2003) IS Success Model. This model has three constructs that were used to assess design considerations: system quality, information quality, and use/user satisfaction. The design recommendations are very similar to the generic recommendations outlined above, but tend to be more focused on specific tactics that KMS designers should use. The main additions are with respect to doing system maintenance and getting users to access the KMS when use is optional. Maintenance recommendations evolved from the observation that many organizations looked at the development of the KMS as a onetime activity and failed to allocate resources to maintain the system or the data, information and knowledge. Organizations also failed to recognize the need for expertise in these systems and failed to add KMS experts to their technical and organizational staffs. Recommendations for improving KMS use came from the need to identify the impact of using the KMS and applying feedback from use to improving or adjusting the knowledge and KMS. This is essential for encouraging voluntary use.
Ultimately the above suggests that KMS designers should include a review of the nature of the organization's work force, the activities performed, and how knowledge is applied. This will allow for a determination of what forms and representations of memory can best serve the particular organization.
SUMMARY
KM is the retention of experience, knowledge, information, and data about events in an organization that are then applied to future events to support decision-making. The KMS is the system an organization builds to support the capture, storage, search, retrieval, and application of knowledge. This includes the management support, processes, and IT applications and components necessary to support these activities. Additionally, the KMS uses a variety of repositories including computer, paper, and self-memory based repositories. Organizations need to design their knowledge repositories based on the transience and experience of their workers. The more transient the users, the more the repositories need to be computer based. Self-memories are used to help less experienced workers gain context so that they can use the computerized repositories; however, the self-memories used are those of experienced workers. The next article will look at those critical success factors that determine if the KMS succeeds.
REFERNCES
- Alavi, M. and Leidner, D.E. (2001). Review: Knowledge Management and Knowledge Management Systems: Conceptual Foundations and Research Issues. MIS Quarterly, 25(1), 107-136.
- Alter, S. (1999). A General, Yet Useful Theory of Information Systems. Communications of the Association for Information Systems, 1(13).
- Binney D. (2001). The Knowledge Management Spectrum: Understanding the KM Landscape. The Journal of Knowledge Management, 5(1), 33-42.
- Borghoff, U.M. and Pareschi, R. (1998). Information Technology for Knowledge Management. Berlin: Springer-Verlag.
- Churchman, C. W. (1979) The Systems Approach (revised and updated) New York: Dell Publishing.
- DeLone, W.H. and McLean, E.R. (1992). Information Systems Success: The Quest for the Dependent Variable. Information Systems Research, 3, 60-95.
- DeLone, W.H. and McLean, E.R. (2003). The DeLone and McLean Model of Information Systems Success: A Ten-Year Update. Journal of Management Information Systems, 19(4), 9-30.
- Eppler, M.J., (2001). Making Knowledge Visible Through Intranet Knowledge Maps: Concepts, Elements, Cases. Proceedings of the Thirty-fourth Hawaii International Conference on System Sciences, HICSS34, IEEE Computer Society.
- Hahn, J. and Subramani, M.R., (2000). A Framework of Knowledge Management Systems: Issues and Challenges for Theory and Practice. Proceedings of the Twenty-first International Conference on Information Systems, Association for Information Systems, 302-312.
- Hobbs, V. and Pigott, D., (2001). Entity-Media Modeling: Conceptual Modeling for Multimedia Database Design. Information Systems Development Conference.
- Hobbs, V. and Pigott, D., (2001). A Methodology for Multimedia Database Design. Information Systems Development Conference.
- Jennex, M.E. and Olfman, L. (2000). Development Recommendations for Knowledge Management/ Organizational Memory Systems. Information Systems Development Conference.
- Jennex, M.E. and Olfman, L., (2002). Organizational Memory/Knowledge Effects On Productivity, A Longitudinal Study. 35th Hawaii International Conference on System Sciences, HICSS35, IEEE Computer Society.
- Jennex, M. E. and Olfman, L. (2004). Modeling Knowledge Management Success. Conference on Information Science and Technology Management, CISTM.
- Maier, R. (2002). Knowledge Management Systems: Information and Communication Technologies for Knowledge Management. Berlin: Springer-Verlag.
- Mandviwalla, M., Eulgem, S., Mould, C., and Rao, S.V. (1998). Organizational Memory Systems Design. Unpublished Working Paper for the Task Force on Organizational Memory, Burstein, F., Huber, G., Mandviwalla, M., Morrison, J., and Olfman, L. (eds.) Presented at the 31st Annual Hawaii International Conference on System Sciences.
- Marwick, A.D., (2001). Knowledge Management Technology. IBM Systems Journal, 40(4), 814-830.
- Morrison, J. and Weiser, M. (1996) A Research Framework for Empirical Studies in Organizational Memory, Proceedings of the Twenty-Ninth Annual Hawaii International Conference on System Sciences, IEEE Computer Society Press.
- Nonaka, I., (1994). A Dynamic Theory Of Organizational Knowledge Creation. Organization Science, 5(1), 14-37.
- Sandoe, K. and Olfman, L., (1992). Anticipating The Mnemonic Shift: Organizational Remembering And Forgetting In 2001. Proceedings of the Thirteenth International Conference on Information Systems, ACM Press.
- Stein, E.W. and Zwass, V., (1995). Actualizing Organizational Memory With Information Systems. Information Systems Research, 6(2), 85-117.
- Zack, M.H., (1999). Managing Codified Knowledge. Sloan Management Review, 40(4), 45-58.
|
|
