|
По словам Карла Фраппаоло (одного из основателей Delphi Consulting Group): «Высокоуровневый поиск знаний — способность искать самую точную и актуальную информацию в огромном числе источников различных типов — будет очень важен для успеха не только сегодняшней работы, но и при подготовке к работе на глобальном рынке XXI века».
ДАННЫЕ... ИНФОРМАЦИЯ... ЗНАНИЯ? Что такое корпоративные знания?
Умение наиболее эффективно распорядиться информационными ресурсами — одно из основных требований успешной деятельности любой организации, работающей в условиях постоянно растущей конкуренции — в конечном итоге нужно говорить о безопасности бизнеса, отрасли и государства в целом.
При этом количество информации, с которой приходиться работать аналитикам, экспертам и руководителям постоянно растет, но количество информации, необходимой для ежедневной работы, для принятия решения примерно постоянно — возникает проблема качества работы с информацией.
Опрос более чем 1300 профессионалов компании Reuters показал, что:
- 25% требуют невероятные объемы информации;
- 38% тратят значительное время на поиски нужной информации;
- 41% считают, что условия работы чрезмерно усложнены;
- 47% считают, что поиск информации отрывает их от основной работы;
- 48% боятся, что Internet станет информационным «червем»;
- 49% чувствуют, что не могут «переварить» полученную информацию;
- 94% не верят в улучшение ситуации
Подводя краткий и неутешительный итог таких исследований, в отчете ЮНЕСКО за 2002 год 74% европейского общества был поставлен «диагноз»: «Синдром информационной усталости — инфофобия».
Информация — еще не знания (до тех пор, пока она не востребована и не решает конкретной задачи).
Деятельность любой организации — процессно-ориентированный поиск требуемых процедурных решений в системе распределенной информации и знаний.
Знания организации (или корпоративные знания) — это та многообразная информация, которую необходимо иметь для поддержки на высоком уровне основных бизнес-процессов организации, а также для быстрого и адекватного реагирования на различные воздействия. Это связано с тем, что:
- знания порождаются только из адекватной задаче информации;
- знание — материализованная и востребованная информация, обладающая свойством добавленного качества;
- документ — это уже материализованная форма востребованной информации.
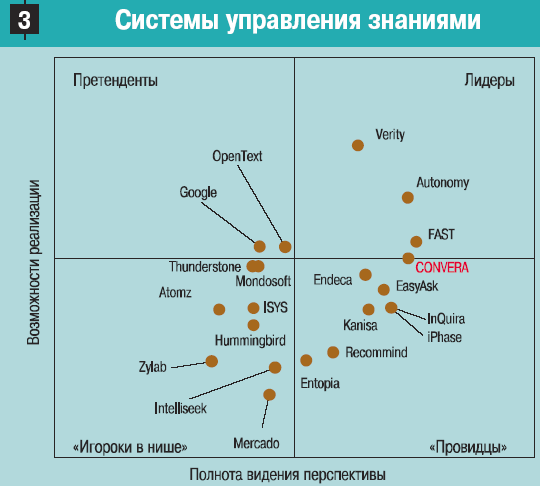
В данном контексте понятно, что системы управления знаниями являются неотьемлемой частью систем поддержки принятия решения. Можно привести классическую схему работы с информацией в процессе анализа и подготовки принятия решений (рис. 1).
Проблема: чем и как искать?
Говоря о том, что необходимо «что-то и где-то» найти, понять, рассмотреть под разными углами зрения, осознать и т. д. давайте попробуем просто подумать над теми трудностями, которые, наверняка, возникают у многих при работе с данными в больших информационных пространствах.
Во-первых, ресурсы Internet часто не решают всего круга задач пользователей — найти там что-то нужное с помощью обычных поисковых систем нелегко. Кроме этого, для любой организации чрезвычайно важна возможность использовать собственный опыт работы в конкретных областях деятельности. Как результат — практически каждая крупная организация создает собственный электронный архив данных (чаще всего в смешанном варианте использования внутренних и внешних информационных ресурсов).
Во-вторых, наибольший объем информации находится в неструктурированном виде. Как правило, это самые разнообразные текстовые, табличные данные, а также фото-, видео- и звуковая информация.
В-третьих, возникает масса проблем при работе с документами на разных языках, с опечатками и ошибками и т. д.
В мире существует много разных систем, которые решают отдельные задачи при работе с электронными данными, почтовыми сообщениями, внутренними документами, внешней информацией.
Сегодня на рынке поисковых систем есть три группы программных продуктов, позволяющих решать только им доступные задачи:
- системы управления знаниями, которые, как правило, могут «почти все»;
- информационно-поисковые системы, которые предлагают новостные ленты, рубрикацию документов с возможностями «минимальной» аналитики;
- поисковые системы для работы с Internet и в intranet — всем известные «поисковики».
Платформа управления знаниями — что это?
В нашем понимании — это решение для организации, интеграции больших информационных массивов, поиска и обнаружения скрытых неочевидных знаний с возможностью накопления и сохранения знаний организации.
Быстрая и гибкая система должна работать вне зависимости от точки доступа, с различными типами хранилищ данных, с разнородной информацией на разных языках.
В связи с этим целесообразно рассмотреть основные требования к системам управления знаниями, предъявляемые к ним на мировом рынке. Ведь использование максимального числа источников данных, высокая скорость обработки запросов, полнота и достоверность результатов — это лишь некоторые характеристики подобных систем управления знаниями.
15 ТРЕБОВАНИЙ К СИСТЕМАМ УПРАВЛЕНИЯ ЗНАНИЯМИ
Эти требования разработаны на основе мирового опыта по разработке, внедрению и эксплуатации систем управления знаниями.
Прежде всего, выделим необходимость реализации различных видов поиска: смысловой, нечеткий и логический. Для всех видов поиска важнейшим является механизм оценки значимости найденных документов, чтобы в первую десятку из списка найденных длиной в тысячу попали действительно наиболее полезные. Кроме тривиальных методов на основе частоты использования искомых слов, система должна учитывать их расположение в документе, в том числе физическое расстояние между словами.
1. Смысловой поиск (расширение поискового запроса близкими по смыслу словами) позволяет пользователю составлять запрос на естественном языке. Реализуется в виде алгоритма поиска по ассоциациям с темой запроса. Этот параметр характеризует качество поисковых систем, так как именно он обеспечивает высокую релевантность найденной информации.
В этом режиме система использует словари и тезаурусы (в качестве базы знаний) для расширения запросов. При этом система автоматически производит расширение запроса терминами, связанными по смыслу с условиями запроса.
Здесь, в первую очередь, имеется в виду возможность использования и учета морфологии и семантики конкретного языка.
Реализация морфологического блока обеспечивает поиск слова в любой его словоформе. Кроме удобства для пользователя, которому не нужно в этом случае использовать шаблоны (Андр* = Андрея, Андрюше...) или сложные логические формулы (Вов* AND Boлод* AND Владимир*), данная технология повышает эффективность поиска за счет существенного сокращения индексных файлов архивов и частичного разрешения омонимии языков.
В базе знаний находится информация о значениях слов, их морфологии, лексике, вариантах написания и связях между словами. Эти связи между словами позволяют объединять их в «семантическую сеть».
Семантический блок автоматически преобразует запросы пользователей на естественном языке в набор связанных по смыслу понятий. Наличие этого блока позволит, например, при запросе «Расписание электричек» найти документ с текстом «Время отправления пригородных поездов». В основе механизма лежит применение семантической сети — ориентированного графа, соединяющего между собой слова и понятия и определяющего весовые коэффициенты этим связям. За счет этого обеспечивается извлечение максимума информации, относящейся к изучаемому вопросу, вне зависимости от того, с использованием каких терминов она описана.
2. Нечеткий поиск обеспечивает поиск слов или элементов текста по схожести написания — имеется возможность искать информацию, зная лишь примерно как она «выглядит». Нечеткий поиск обеспечивает извлечение информации как со случайно, так и с намеренно внесенными изменениями (например, поиск в базах фамилий и т. п. сведений о человеке, даже если его фамилия искажена — отсутствуют, стерты, подделаны буквы).
Наличие опечаток и ошибок в текстовой информации — явление достаточно распространенное. Использование нечеткого поиска позволит исключить трудоемкие операции проверки орфографии и исправления ошибок после работы автоматических систем распознавания текста.
Нечеткий поиск основан не на точном совпадении слов документа и запроса, а на исчислении меры их близости. Применительно к текстовым документам это означает решение проблемы опечаток, ошибок преобразования при оптическом распознавании текста, появления неологизмов с неустоявшимся правописанием (к примеру, до сих пор разные издания используют термины «браузер» и «броузер»).
Такой подход может оказаться полезным при поиске в «грязных документах», получаемых после OCR-обработки отсканированного текста, или при поиске слов с несколькими вариантами написания или сложным написанием.
Кроме того, данная технология позволяет исключить дорогостоящий и трудоемкий этап правки документов после распознавания текста, что позволяет быстро перевести объемные архивы бумажных документов в электронный вид (до нескольких тысяч машинописных листов в день с одного рабочего места) — режим ретроконверсии.
Для нечеткого поиска информации применяется механизм адаптивного распознавания образов APRP (Adaptive Pattern Recognition Processing), который зародился в процессе исследований в области моделирования сложных биологических систем. Для обработки информации в нем используются нейронные сети, механизм действует, как самоорганизующаяся система, автоматически формирующая и индексирующая двоичные образы документов. Данная технология обеспечивает поддержку нечеткого поиска информации, его высокую точность и полноту, языковую независимость и малый объем индексных файлов. Но главное, что APRP можно применять фактически для любой информации, представленной в электронном виде, — текстов, изображений, звуков, видео.
3. Логический (булевский) поиск обеспечивает высокую точность извлечения информации по специфическим запросам, но требует от пользователя хорошего знания предмета исследования.
В режиме логического поиска можно использовать операторы алгебры логики (OR, AND, NOT, WITHIN) и быстро находить документы, содержащие (или не содержащие) определенные слова и иные элементы текста. Кроме использования обычных логических операторов, желательно иметь возможность задавать ограничения расстояния между словами, порядок следования слов, использовать функции нечеткого и семантического расширения слов, операторы поиска по диапазонам чисел и дат и т. п.
4. Функциональная расширяемость и открытая архитектура для систем управления знаниями стали общепринятыми. Только открытая система может предоставлять разработчикам возможности адаптации системы к условиям местного рынка, а также тонкой настройки системы под требования заказчика. Требования открытости архитектуры системы должны распространяться на все модули системы вплоть до ядра.
Особо нужно отметить необходимость в системе средств разработки, которые должны быть доступны пользователям, разработчикам и системным интеграторам для создания приложений для полнотекстового и атрибутивного поиска, различные Web-интерфейсы для пользователей, а также возможность дополнять интерфейсы специализированными функциональными клавишами.
Средства разработки дают возможность интегрировать систему в существующее информационное окружение.
5. Многоязыковая и кросс-языковая поддержка — дорогое, но вполне объяснимое требование к системе. В быстро развивающемся мире с взаимной интеграцией и переплетением интересов политики и бизнеса разных стран — это реальная необходимость.
В этом случае пользователи системы должны быть полиглотами или же их должно быть достаточно для обеспечения работы с разными документами на разных языках мира.
Для решения таких проблем существует так называемый режим «кросс-языковой» поддержки, когда запрос выполняется на одном языке, а ответы (информацию) пользователь получает на другом (или других) . Должна быть также предусмотрена возможность перевода «на лету» получаемой информации для оперативного ее изучения.
В системах управления знаниями многоязыковая и лингвистическая поддержка обеспечивается на основе создания и разработки:
- семантических сетей, которые представляют объекты реального мира как связанные между собой понятия с их отношениями и взаимосвязями;
- предметных классификаторов (таксономий), представляющих собой разветвленные иерархии понятий и объектов анализа;
- тезаурусов — списков с системой перекрестных ссылок, необходимых для организации коллекций документов при их отыскании, отображении и хранения.
Лингвистические ресурсы системы должны иметь открытую архитектуру — это позволяет пользователям дополнять систему своими специализированными словарями, тезаурусами и таксономиями, отражающими специфику конкретной предметной области со всеми ее терминами, объектами и связями.
Во всем мире подобные задачи решаются на государственном уровне. Работы по расширению понятий в разных областях знаний ведутся, и нужно отметить, что для многих областей знаний и деятельности человека необходимо разрабатывать лингвистические ресурсы с учетом специфики терминологии и связей между понятиями.
К сожалению, до последнего времени в Украине такие масштабные работы для украинского языка (и кросс-языковых систем) просто не велись.
6. Работа с видео/аудио информацией — одно из реальных требования. Здесь речь идет не просто о «мультимедиа» информации, а о возможностях системы не только формировать базы и архивы фото, аудио и видео файлов, а и оперативно управлять информацией, содержащейся в них.
Обычно такая работа системы основана на построении удобного для пользователя представления видеороликов в виде последовательности характерных кадров, на которых отображается одно действие (или же тот фрагмент, который необходим для анализа). Например, можно получить подборку выступления политика, бизнесмена о какой-то проблеме, теме. Вместе с видеоинформацией хранятся и метаданные (атрибутивная информация, субтитры, распознанный звук и т. п.).
Система должна позволять осуществлять поиск похожих кадров (или аудио фрагментов) по ее соответствию изображения (звуку) запросу, а также выполнять другие действия с графической информацией.
7. Персонификация работы, сохранение и обмен знаниями — ключевой момент в управлении знаниями. Все, что создано аналитиками и экспертами организации сохраняется в виде тех интеллектуальных ресурсов, которые были ими разработаны, апробированы и использовались в работе.
Кроме этого, система должна позволять пользователю создавать наборы собственных лингвистических ресурсов, персонализированных фильтров, собственные уникальные поисковые интерфейсы, оповещения о появлении искомой информации и распространять результаты исследовательской и аналитический работы между пользователями системы с помощью публичных папок.
8. Локализация областей исследования позволит минимизировать информационный шум во время работы. Использование специализированных словарей (тезаурусов), таксономии по различным предметным областям и одновременно персональных библиотек (по сути — информационных зон) предоставляют возможность пользователям проводить исследования по отдельным сферам интересов «не мешая друг другу» и «не путая специфические термины».
9. Поддержка разнообразных форматов документов — необходимое требование к системе управления знаниями. Это связано с тем, что в каждой организации сложилась и существует своя информационная среда, и исходные документы могут быть представлены в самых разных форматах. Поэтому система должна обеспечивать эффективную работу практически с любыми форматами документов, охватывающих все типы приложений (а их более 200), таких как Internet (HTML, XML, PDF), Word Processing (MS Word, WordPerfect, Mac Write, PageMaker), Spreadsheets (Excel, Lotus 1-2-3, Quattro), Presentations (PowerPoint, Persuasion, Visio), Graphics (Corel, Illustrator, Free-Hand, Micrografx), которые могут храниться в структурированном и неструктурированном виде.
Но, помимо поддержки широкого числа форматов, желательно, чтобы пользователь мог оперативно изменять предоставляемые системой и подключать к системе собственные конверторы.
10. Поддержка широкого круга источников. Информация может находиться в источниках разного рода, например:
- файлах, находящихся в файловой системе компьютеров в LAN или WAN;
- системах управления базами данных (Oracle, MS SQL, Sybase, Informix, Teradata и иных СУБД);
- почтовых и корпоративных системах (MS Exchange, Lotus);
- системах документооборота (Documentum, File-Net Panagon);
- HTML-страницах;
- различных архивах и т. д.
Система должна поддерживать все многообразие источников и хранилищ данных.
Важнейшим параметром системы является возможность автоматического сбора информации в сетях Internet и intranet. Поиск, как правило, выполняется в соответствии с установками пользователя (типы документов, глубина и широта обхода сайта, частота обновления и пр.); результаты заносятся в специализированную базу данных.
Кроме удобства работы и упрощения добычи информации из Internet, эта опция решает задачу информационной безопасности организации — сотрудники организации обеспечиваются неограниченной информацией из Internet без непосредственной работы в глобальной сети.
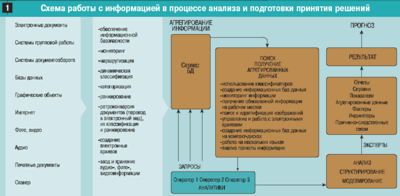
11. Динамическая классификация предлагает пользователю системы комбинировать классификаторы в разных вариантах, обеспечивая оперативное построение динамически формируемых матриц, изменяющихся в ходе процесса осмысления изучаемого материала. В этом случае информация отображается в виде таблицы, позволяющей выполнять многомерный анализ, изучая тему под разными углами зрения и в разных контекстах (рис. 2).
Для аналитиков и экспертов важнейшим в исследованиях является контроль полноты имеющейся информации в работе. И именно динамическая классификация (в многомерной матрице) покажет по каким темам исследования и в каких информационных срезах отсутствует информация по данной теме изучения проблемы.
12. Масштабируемость по объему. Уже в настоящее время многие аналитические группы сталкиваются с тем, что ежедневно объемы поступающей для анализа информации исчисляется десятками гигабайт, а что ждет их дальше тяжело предвидеть. Ясно одно — скоро массивы накопленной информации будут исчисляться терабайтами и петабайтами.
Одно из ключевых требований к поисковым системам — масштабируемость как по объему обрабатываемой информации, так и по числу пользователей.
Нужно отметить, что поддержка больших информационных массивов в целом не составляет проблемы. Но вопрос состоит в том, как зависит от объема информации скорость поиска. К сожалению, реальные показатели быстродействия очень сложно определить теоретически, для их получения нужны тестовые испытания, а еще лучше — в рамках действующих проектов. Именно такие тестирования показали, что немногие системы решают эти проблемы. Оптимальным решением на сегодняшний день является разбиение общего массива на несколько частей и размещение этих частей на отдельных аппаратных платформах. То есть создание кластеров данных и композитных библиотек.
Для пользователей физическое разделение данных должно быть совершенно прозрачно и составлять единое информационное пространство. Поэтому возможность создания кластерных решений должна быть заложена в системе изначально. В противном случае система скорее всего представляет собой так называемую «настольную» систему управления знаниями, или пользователь будет вынужден постоянно покупать все более новые аппаратные средства для обеспечения требований растущей системы, при этом старые аппаратные средства будут оставаться мертвым грузом.
С точки зрения обслуживания пользователей, система должна иметь значительный «запас прочности» для того, чтобы увеличение количества одновременно работающих с системой пользователей не приводило к существенному повышению времени выполнения запросов.
13. Информационный поток обновлений. Некоторые поисковые механизмы приостанавливают доступ к архиву на время переиндексации при подключении новой информации. Если же объем информации быстро разрастается, то, естественно, существенно увеличивается и время реиндексации информации. Поэтому важными требованиями к системе являются «интеллектуальная» реиндексация, то есть возможность индексации только новой и измененной информации без затрагивания общего объема, а также неблокирование доступа к системе на время реиндексации. Невыполнение одного из этих требований приводит к существенным задержкам в обновлении информационной базы системы, а невыполнение обоих — к значительным простоям в работе пользователей и, как результат, сбоям в аналитической работе специалистов.
14. Аппаратно-программная платформа. Повышение производительности конкретной прикладной системы может быть реализовано за счет смены аппаратно-программной платформы, а также использования многопроцессорных и многосерверных конфигураций. Поэтому одним из главных требований к современным системам является поддержка большинства существующих программно-аппаратных платформ, таких как Microsoft Windows NT, UNIX (Sun Solaris, Linux, IBM/AIX, HP-UX) и т. д. Немаловажным фактором также является возможность организации кросс-платформенной работы системы.
При создании распределенных информационно-аналитических систем весьма важно обеспечить простой доступ к системе большому количеству пользователей. Как правило, в таких системах клиентским местом служит любой Web-браузер, что позволяет иметь доступ к системе без специального клиентского ПО.
15. Защита информации. Развитая система безопасности, наследующая свойства безопасности источников информации, должна позволять использовать систему управления знаниями как средство для создания территориально распределенных автоматизированных систем с обеспечением контроля доступа на уровне отдельных документов, возможностью передачи данных в зашифрованном виде, а также обеспечивать гибкое управление правами пользователя.
Система контроля доступа аутентифицирует и авторизует каждого пользователя при входе в систему. Для каждого документа определяется круг (группы) пользователей, которым разрешена работа с указанным документом. Должна существовать система наследования прав доступа к документам.
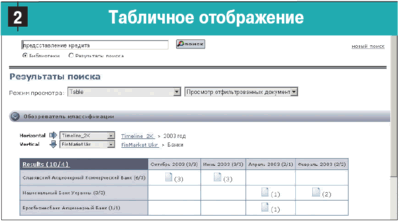
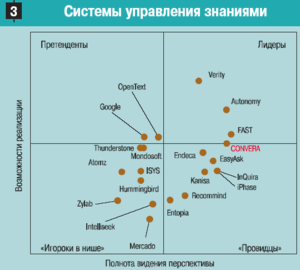
Из всего сказанного можно сделать вывод: только система, соответствующая перечисленным требованиям должна позиционироваться как система управления знаниями — требования очень масштабные и жесткие — но только такая система решит то множество задач по управлению организацией и безопасности ее деятельности. Из мировых лидеров, по материалам Gartner Group (см. рис. 3), в Украине представлена лишь Convera Technologies.
Что касается области применения, можно сказать коротко: системы управления знаниями необходимы везде, где существуют задачи по работе с большими объемами разнородной информации, где необходимо оперативно решать задачи управления, исследования и безопасности. В первую очередь, это относится к государственному управлению и безопасности, большому бизнесу, научной и исследовательской работе, практической работе во многих областях знаний.
Об авторе:
Комов Сергей Анатольевич — директор по развитию бизнеса, «ЭйЭнТи».
|