На сегодняшний день наука достаточно далеко продвинулась в разработке технологий прогнозирования. Специалистам хорошо известны методы нейросетевого прогнозирования, нечёткой логики и т.п. Разработаны соответствующие программные пакеты, но на практике они, к сожалению, не всегда доступны рядовому пользователю, а в то же время многие из этих проблем можно достаточно успешно решать, используя методы исследования операций, в частности имитационное моделирование, теорию игр, регрессионный и трендовый анализ, реализуя эти алгоритмы в широко известном и распространённом пакете прикладных программ MS Excel.
В данной статье представлен один из возможных алгоритмов построения прогноза объёма реализации для продуктов с сезонным характером продаж. Сразу следует отметить, что перечень таких товаров гораздо шире, чем это кажется. Дело в том, что понятие "сезон" в прогнозировании применим к любым систематическим колебаниям, например, если речь идёт об изучении товарооборота в течение недели под термином "сезон" понимается один день. Кроме того, цикл колебаний может существенно отличаться (как в большую, так и в меньшую сторону) от величины один год. И если удаётся выявить величину цикла этих колебаний, то такой временной ряд можно использовать для прогнозирования с использованием аддитивных и мультипликативных моделей.
Аддитивную модель прогнозирования можно представить в виде формулы:
F = T + S + E
где:
F — прогнозируемое значение; Т — тренд; S — сезонная компонента; Е — ошибка прогноза.
Применение мультипликативныхмоделей обусловлено тем, что в некоторых временных рядах значение сезонной компоненты представляет собой определенную долю трендового значения. Эти модели можно представить формулой:
F = T х S x E
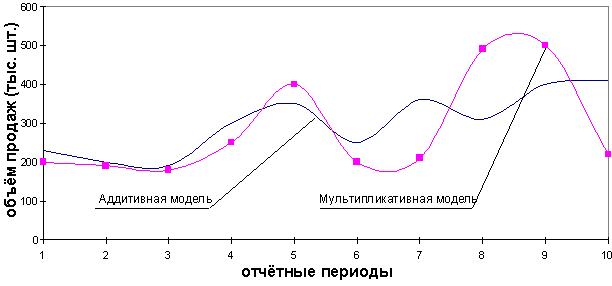
На практике отличить аддитивную модель от мультипликативной можно по величине сезонной вариации. Аддитивной модели присуща практически постоянная сезонная вариация, тогда как у мультипликативной она возрастает или убывает, графически это выражается в изменении амплитуды колебания сезонного фактора, как это показано на рисунке 1.
Рис. 1. Аддитивная и мультипликативные модели прогнозирования
Алгоритм построения прогнозной модели
Для прогнозирования объема продаж, имеющего сезонный характер, предлагается следующий алгоритм построения прогнозной модели:
1. Определяется тренд, наилучшим образом аппроксимирующий фактические данные. Существенным моментом при этом является предложение использовать полиномиальный тренд, что позволяет сократить ошибку прогнозной модели.
2. Вычитая из фактических значений объёмов продаж значения тренда, определяютвеличины сезонной компоненты и корректируют таким образом, чтобы их сумма была равна нулю.
3. Рассчитываются ошибки модели как разности между фактическими значениями и значениями модели.
4. Строится модель прогнозирования:
F = T + S ± E
где:
F— прогнозируемое значение;
Т— тренд;
S — сезонная компонента;
Е — ошибка модели.
5. На основе модели строится окончательный прогноз объёма продаж. Для этого предлагается использовать методы экспоненциального сглаживания, что позволяет учесть возможное будущее изменение экономических тенденций, на основе которых построена трендовая модель. Сущность данной поправки заключается в том, что она нивелирует недостаток адаптивных моделей, а именно, позволяет быстро учесть наметившиеся новые экономические тенденции.
Fпр t = a Fф t-1 + (1-а) Fм t
где:
Fпр t — прогнозное значение объёма продаж;
Fф t-1 — фактическое значение объёма продаж в предыдущем году;
Fм t — значение модели;
а — константа сглаживания
Практическая реализация данного метода выявила следующие его особенности:
для составления прогноза необходимо точно знать величину сезона. Исследования показывают, что множество продуктов имеют сезонный характер, величина сезона при этом может быть различной и колебаться от одной недели до десяти лет и более;
применение полиномиального тренда вместо линейного позволяет значительно сократить ошибку модели;
при наличии достаточного количества данных метод даёт хорошую аппроксимацию и может быть эффективно использован при прогнозировании объема продаж в инвестиционном проектировании.
Применение алгоритма рассмотрим на следующем примере.
Исходные данные: объёмы реализации продукции за два сезона. В качестве исходной информации для прогнозирования была использована информация об объёмах сбыта мороженого “Пломбир” одной из фирм в Нижнем Новгороде. Данная статистика характеризуется тем, что значения объёма продаж имеют выраженный сезонный характер с возрастающим трендом. Исходная информация представлена в табл. 1.
Таблица 1. Фактические объёмы реализации продукции
№п.п.
Месяц
Объем продаж (руб.)
№п.п.
Месяц
Объем продаж (руб.)
1
июль
8174,40
13
июль
8991,84
2
август
5078,33
14
август
5586,16
3
сентябрь
4507,20
15
сентябрь
4957,92
4
октябрь
2257,19
16
октябрь
2482,91
5
ноябрь
3400,69
17
ноябрь
3740,76
6
декабрь
2968,71
18
декабрь
3265,58
7
январь
2147,14
19
январь
2361,85
8
февраль
1325,56
20
февраль
1458,12
9
март
2290,95
21
март
2520,05
10
апрель
2953,34
22
апрель
3248,67
11
май
4216,28
23
май
4637,91
12
июнь
8227,569
24
июнь
9050,3264
Задача: составить прогноз продаж продукции на следующий год по месяцам.
Реализуем алгоритм построения прогнозной модели, описанный выше. Решение данной задачи рекомендуется осуществлять в среде MS Excel, что позволит существенно сократить количество расчётов и время построения модели.
1. Определяем тренд, наилучшим образом аппроксимирующий фактические данные. Для этого рекомендуется использовать полиномиальный тренд, что позволяет сократить ошибку прогнозной модели).
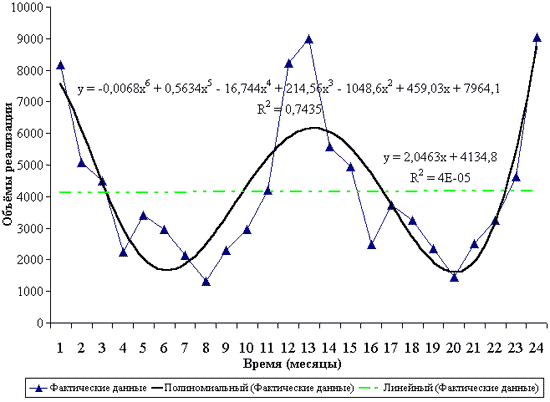
Рис. 2. Сравнительный анализ полиномиального и линейного тренда
На рисунке показано, что полиномиальный тренд аппроксимирует фактические данные гораздо лучше, чем предлагаемый обычно в литературе линейный. Коэффициент детерминации полиномиального тренда (0,7435) гораздо выше, чем линейного (4E-05). Для расчёта тренда рекомендуется использовать опцию “Линия тренда” ППП Excel.
Рис. 3. Опция "Линии тренда"
Применение других типов тренда (логарифмический, степенной, экспоненциальный, скользящее среднее) также не даёт такого эффективного результата. Они неудовлетворительно аппроксимируют фактические значения, коэффициенты их детерминации ничтожно малы:
логарифмический R2 = 0,0166;
степенной R2 = 0,0197;
экспоненциальный R2 = 8Е-05.
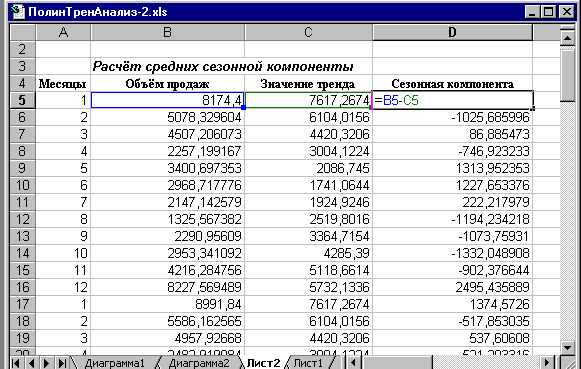
2. Вычитая из фактических значений объёмов продаж значения тренда, определим величины сезонной компоненты, используя при этом пакет прикладных программ MS Excel (рис. 4).
Рис. 4. Расчёт значений сезонной компоненты в ППП MS Excel
Таблица 2. Расчёт значений сезонной компоненты
Месяцы
Объём продаж
Значение тренда
Сезонная компонента
1
8174,4
7617,2674
557,1326
2
5078,3296
6104,0156
-1025,686
3
4507,2061
4420,3206
86,885473
4
2257,1992
3004,1224
-746,92323
5
3400,6974
2086,745
1313,95235
6
2968,7178
1741,0644
1227,65338
7
2147,1426
1924,9246
222,217979
8
1325,5674
2519,8016
-1194,2342
9
2290,9561
3364,7154
-1073,7593
10
2953,3411
4285,39
-1332,0489
11
4216,2848
5118,6614
-902,37664
12
8227,5695
5732,1336
2495,43589
1
8991,84
7617,2674
1374,5726
2
5586,1626
6104,0156
-517,85304
3
4957,9267
4420,3206
537,60608
4
2482,9191
3004,1224
-521,20332
5
3740,7671
2086,745
1654,02209
6
3265,5896
1741,0644
1524,52515
7
2361,8568
1924,9246
436,932237
8
1458,1241
2519,8016
-1061,6775
9
2520,0517
3364,7154
-844,6637
10
3248,6752
4285,39
-1036,7148
11
4637,9132
5118,6614
-480,74817
12
9050,3264
5732,1336
3318,19284
Скорректируем значения сезонной компоненты таким образом, чтобы их сумма была равна нулю.
Таблица 3. Расчёт средних значений сезонной компоненты
Месяцы
1-й сезон
2-й сезон
Итого
Среднее
Сезонная компонента
1
557,1326
1374,5726
1931,7052
965,8526
798,7176058
2
-1025,686
-517,853035
-1543,539
-771,7695155
-938,90451
3
86,885473
537,60608
624,491553
312,2457765
145,1107823
4
-746,92323
-521,203316
-1268,1265
-634,0632745
-801,198269
5
1313,9524
1654,022089
2967,97444
1483,987221
1316,852227
6
1227,6534
1524,525154
2752,17853
1376,089265
1208,954271
7
222,21798
436,932237
659,150216
329,575108
162,4401138
8
-1194,2342
-1061,677479
-2255,9117
-1127,955849
-1295,09084
9
-1073,7593
-844,663701
-1918,423
-959,2115055
-1126,3465
10
-1332,0489
-1036,714798
-2368,7637
-1184,381853
-1351,51685
11
-902,37664
-480,748169
-1383,1248
-691,5624065
-858,697401
12
2495,4359
3318,192838
5813,62873
2906,814363
2739,679369
Сумма
2005,61993
0
3. Рассчитываем ошибки модели как разности между фактическими значениями и значениями модели.
Таблица 4. Расчёт ошибок
Месяц
Объём продаж
Значение модели
Отклонения
1
8174,4
8415,985006
-241,585006
2
5078,3296
5165,11109
-86,7814863
3
4507,2061
4565,431382
-58,2253093
4
2257,1992
2202,924131
54,27503571
5
3400,6974
3403,597227
-2,89987379
6
2968,7178
2950,018671
18,69910521
7
2147,1426
2087,364714
59,77786521
8
1325,5674
1224,710757
100,8566247
9
2290,9561
2238,3689
52,58718971
10
2953,3411
2933,873153
19,46793921
11
4216,2848
4259,963999
-43,6792433
12
8227,5695
8471,812969
-244,24348
13
8991,84
8415,985006
575,8549942
14
5586,1626
5165,11109
421,0514747
15
4957,9267
4565,431382
392,4952977
16
2482,9191
2202,924131
279,9949527
17
3740,7671
3403,597227
337,1698622
18
3265,5896
2950,018671
315,5708832
19
2361,8568
2087,364714
274,4921232
20
1458,1241
1224,710757
233,4133637
21
2520,0517
2238,3689
281,6827987
22
3248,6752
2933,873153
314,8020492
23
4637,9132
4259,963999
377,9492317
24
9050,3264
8471,812969
578,5134687
Находим среднеквадратическую ошибку модели (Е) по формуле:
Е= Σ О2 : Σ (T+S)2
где:
Т — трендовое значение объёма продаж;
S — сезонная компонента;
О — отклонения модели от фактических значений
Е= 0,003739 или 0.37 %
Величина полученной ошибки позволяет говорить, что построенная модель хорошо аппроксимирует фактические данные, т.е. она вполне отражает экономические тенденции, определяющие объём продаж, и является предпосылкой для построения прогнозов высокого качества.
Построим модель прогнозирования:
F = T + S ± E
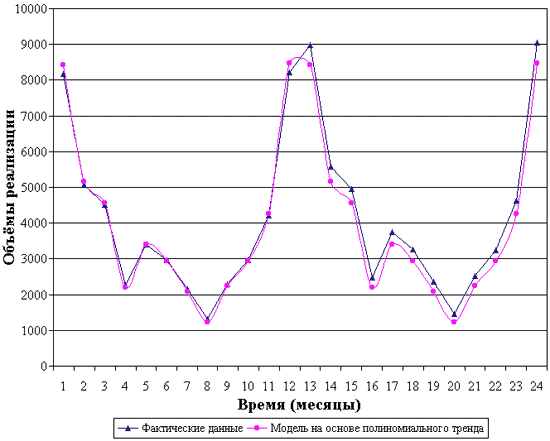
Построенная модель представлена графически на рис. 5.
5. На основе модели строим окончательный прогноз объёма продаж. Для смягчения влияния прошлых тенденций на достоверность прогнозной модели, предлагается сочетать трендовый анализ с экспоненциальным сглаживанием. Это позволит нивелировать недостаток адаптивных моделей, т.е. учесть наметившиеся новые экономические тенденции:
Fпр t = a Fф t-1 + (1-а) Fм t
где:
Fпр t — прогнозное значение объёма продаж;
Fф t-1 — фактическое значение объёма продаж в предыдущем году;
Fм t — значение модели;
а — константа сглаживания.
Константу сглаживания рекомендуется определять методом экспертных оценок, как вероятность сохранения существующей рыночной конъюнктуры, т.е. если основные характеристики изменяются / колеблются с той же скоростью / амплитудой что и прежде, значит предпосылок к изменению рыночной конъюнктуры нет, и следовательно а ® 1, если наоборот, то а ® 0.
Рис. 5. Модель прогноза объёма продаж
Таким образом, прогноз на январь третьего сезона определяется следующим образом.
Определяем прогнозное значение модели:
Fм t = 1 924,92 + 162,44 = 2087 ± 7,8 (руб.)
Фактическое значение объёма продаж в предыдущем году (Fф t-1) составило 2 361 руб. Принимаем коэффициент сглаживания 0.8. Получим прогнозное значение объёма продаж:
Fпр t = 0,8*2 361 + (1-0.8)*2087 = 2306,2 (руб.)
Для учёта новых экономических тенденций рекомендуется регулярно уточнять модель на основе мониторинга фактически полученных объёмов продаж, добавляя их или заменяя ими данные статистической базы, на основе которой строится модель.
Кроме того, для повышения надёжности прогноза рекомендуется строить все возможные сценарии прогноза и рассчитывать доверительный интервал прогноза.
Авторская справка:
Дмитриев Михаил Николаевич, заведующий кафедрой экономики и предпринимательства Нижегородского архитектурно-строительного университета (ННГАСУ), доктор экономических наук, профессор.
Кошечкин Сергей Александрович, кандидат экономических наук, ст. преподаватель кафедры экономики и предпринимательства Нижегородского архитектурно-строительного университета (ННГАСУ), ksa-ii@miepm.sandy.ru.
Алексей, alex-ger@yugcontract.com.ua Ради интереса решил попробовать на конкретных фактических данных - взял историю нескольких лет и попробовал, что бы дал прогноз помесячно во втором полугодии 2003 года. Увы, отклонения чудовищны относительно уже состоявшегося факта.
Вывод: модель можно использовать при отсутствии значимых факторов, влияющих на объёмы продаж; тогда одной статистикой продаж не обойтись.
Юра из Киева, drvlas@gmx.net УФ! Я не сразу разобрался, куда что посылать. Хотел обратиться ко всем, а попал к Алексею. Поэтому повторяю свое вчерашнее сообщение.
На мой взгляд, авторы увлеклись использованием доступного инструмента (Эксель), что само по себе очень хорошо, но очень заблуждаются в прогнозировании. Они подробно описывают, как можно дать АНАЛИТИЧЕСКОЕ ОПИСАНИЕ ИМЕЮЩИХСЯ ДАННЫХ (за те 2 года продаж мороженного нашим русским братьям). Да, так можно построить модель. Кстати, не только так - методов существует множество. И выбирать модель лучше с учетом СУТИ описываемого процесса. Например, если в его основе лежат периодические колебания, может оказаться очень полезной модель в виде ряда Фурье. Но это отдельная тема.
Итак, авторы описали "прошлое". Посчитали ошибку - и восхитились. И тут же - фантастический вывод:
"Величина полученной ошибки позволяет говорить, что построенная модель хорошо аппроксимирует фактические данные, т.е. она вполне отражает экономические тенденции, определяющие объём продаж, и является предпосылкой для построения прогнозов высокого качества."
Да откуда же следует, что полученная модель что-то там отражает? И является предпосылкой для прогнозов?
Скажу иначе. Какой смысл с точностью до долей % описывать то, что было, если разница в "одноименных" месяцах парвого и второго года составляет порядка 10%? Мы имеем процесс с сильной случайной составляющей, которая ограничивает возможную точность прогноза и уж конечно не позволит выйти на погрешности в доли процента. Совершенствование прогнозов в таких случаях основано на увеличении статистики - до той степени, пока не начинает мешать нестационарность процесса. В нашем случае, привлечение данных еще по нескольким годам может только навредить, т.к. за такой период произошли существенные изменения в данном процессе и считать его стационарным нельзя ни в каком приближении. Вот и получается, что с имеющейся случайной составляющей мы можем довольно приблизительно кое-что предсказать. Но описывать процесс так старательно вовсе не обязательно. Есть метод и попроще - будут желающие, поделюсь.
Мои слова подтверждаются и замечанием Алексея.
И еще одно. Сама матоснова прогнозирования также должна опираться на предположения о характере процесса. Поэтому "универсального" алгоритма и не существует. Где-то можно и пренебречь случайной составляющей. Но не в приведенном примере, ИМХО.
D!G.ua В примере фактические данные одного года по месяцам уж оччень пропорциональны факту другого года в тех же месяцах. Другими словами, в примере слишком подавляющее влияние сезонного фактора. А в таком случае прогнозы делать очень легко на факте предыдущих лет. Так что пример не показателен. А вот если бы скажем, в 9-10й месяцы одного года был "нетипичный" провал/пик (на 20%)- погрешность сразу увеличивается до неприемлемых размером. И статистические методы очень плохо работают.
Юра из Киева, drvlas@gmx.net Коллеги, ко мне обращаются за моим таинственным методом прогнозирования. Отвечу здесь, чтобы было доступно всем.
Это не мой метод. В одном из дипломных курсов Школы Бизнеса Лондонского Открытого университета нам приводили нечто подобное, я немного исказил для своих нужд. Более того, использование его в условиях моего
предприятия дает мало пользы. У нас крупнодискретная реализация, за
месяц может быть около десятка продаж. И очень велика случайная
составляющая. Поэтому и точность прогноза невелика.
Однако я допускаю, что в условиях квазинепрерывного потока продаж и
несколько меньшего влияния случайных факторов может быть польза.
Идея же состоит в том, что мы пытаемся прогнозировать по такой
матмодели, которая, НА НАШ ВЗГЛЯД, соответствует реальным
зависимостям. Уже отсюда следует, что УНИВЕРСАЛЬНОГО метода быть не
может. И как ни описывай (очччень точно!) полиномиальными моделями
процесс, у которого налицо периодическая составляющая - для прогноза
это не годится. Аналогично, если в процессе очень сильна случайная
составляющая, то лучше, чем фильтрация ничего нет. Мы просто фильтруем
и берем это ("среднее") значение в качестве прогнозного. Все. Это даст
наименьшуюю ошибку. Естественно, если другие факторы (кроме случайного
шума) слабы. И т.д.
Нужен пример. Пусть мы предполагаем в процесс просто шум. Т.е. модель
того, что мы прогнозируем: постоянная составляющая + шум (с нулевым
средним значением). Тогда алгоритм прогноза: по всем имеющимся данным
находим среднее и считаем это прогнозом.
Теперь мы решили, что в процессе есть и шум, и тренд (это определяется
обработкой даже в Экселе). Тогда строим линию тренда (при этом шум
автоматически фильтруется) и ее продолжение за текущий момент -
наилучший прогноз.
Пусть теперь нам пришло в голову, что в процессе есть периодичность
(продажи очень часто имеют недельную, месячную или годовую
периодичность). Тогда следует решить, какой функцией описать эту
периодичность, найти параметры данной функции по известным данным - и
затем продолжить ее в область будущего. Если функция близка к синусу -
можно просто определить ее частоту, амплитуду и фазу. Но если функция
искажена, то для ее хорошего описания потребуется находить параметры
нескольких гармоник (спектр). Это может быть громоздко. Тогда можно
просто найти т.н. "структуру" в пределах периода. Например, период -
неделя. Тогда можно найти, что в среднем продажи в понедельник
отличаются от среднего значения за предыдущие 7 дней на минус 14%, во
вторник - на минус 15%, а в субботу - на плюс 33% от этого же
среднего. Эти числа назовем коэффициентами структуры. Дальше просто -
продлеваем среднее (просто усреднением или как линию тренда - см.
предыдущие примеры) на будущее, а к ней прибавляем произведение этого
же среднего на коэффициент структуры.
Путано? Пожалуй. Кто сам пробовал - поймет. Кто знает больше -
поправит или предложит свое. Главное в описанном подходе - изучаем
исходные данные не для точного их описания, а для решения об
адекватной модели. Затем ищем параметры модели - и продлеваем эту
функцию в будущее. Угадали модель - прогноз лучше. Шумы мешают. Но
увеличение длительности наблюдения чревато тем, что для построения
модели мы начинаем использовать такие старые данные, что поведение
процесса уже существенно изменилось. Что ж, подбираем оптимум,
набиваем шишки, влетаем в убытки, банкротим предприятие, переходим в
другое, но уже с чуством огромного опыта за плечами :)
У меня есть примерчик на Экселе. ВОт его не знаю, как выложить. Пожалуй, снова подожду - если не разочаровал вас словами - обращайтесь, пришлю табличку.
С уважением и благодарностью к заинтересовавшимся и в надежде на конструктивную критику.
Елена, lenao@sitsy.tpi.ru Юра, умоляю,скинь файлик с текстовкой и XLS посмотреть. О прогнозировании продаж. Мы как ни крутили, цифры получаются с большими отклонениями.